Disaster recovery for planned failover (PREMIUM SELF)
The primary use-case of Disaster Recovery is to ensure business continuity in the event of unplanned outage, but it can be used in conjunction with a planned failover to migrate your GitLab instance between regions without extended downtime.
As replication between Geo sites is asynchronous, a planned failover requires a maintenance window in which updates to the primary site are blocked. The length of this window is determined by your replication capacity - when the secondary site is completely synchronized with the primary site, the failover can occur without data loss.
This document assumes you already have a fully configured, working Geo setup. Read this document and the Disaster Recovery failover documentation in full before proceeding. Planned failover is a major operation, and if performed incorrectly, there is a high risk of data loss. Consider rehearsing the procedure until you are comfortable with the necessary steps and have a high degree of confidence in being able to perform them accurately.
Not all data is automatically replicated
If you are using any GitLab features that Geo doesn't support, you must make separate provisions to ensure that the secondary site has an up-to-date copy of any data associated with that feature. This may extend the required scheduled maintenance period significantly.
A common strategy for keeping this period as short as possible for data stored
in files is to use rsync to transfer the data. An initial rsync can be
performed ahead of the maintenance window; subsequent rsyncs (including a
final transfer inside the maintenance window) then transfers only the
changes between the primary site and the secondary sites.
Repository-centric strategies for using rsync effectively can be found in the
moving repositories documentation; these strategies can
be adapted for use with any other file-based data, such as GitLab Pages.
Container registry
By default, the container registry is not automatically replicated to secondary sites and this needs to be manually configured, see Container Registry for a secondary site.
If you are using local storage on your current primary site for the container
registry, you can rsync the container registry objects to the secondary
site you are about to failover to:
# Run from the secondary site
rsync --archive --perms --delete root@<geo-primary>:/var/opt/gitlab/gitlab-rails/shared/registry/. /var/opt/gitlab/gitlab-rails/shared/registryAlternatively, you can back up the container registry on the primary site and restore it onto the secondary site:
-
On your primary site, back up only the registry and exclude specific directories from the backup:
# Create a backup in the /var/opt/gitlab/backups folder sudo gitlab-backup create SKIP=db,uploads,builds,artifacts,lfs,terraform_state,pages,repositories,packages -
Copy the backup tarball generated from your primary site to the
/var/opt/gitlab/backupsfolder on your secondary site. -
On your secondary site, restore the registry following the Restore GitLab documentation.
Preflight checks
NOTE:
In GitLab 13.7 and earlier, if you have a data type with zero items to sync,
this command reports ERROR - Replication is not up-to-date even if
replication is actually up-to-date. This bug was fixed in GitLab 13.8 and
later.
Run this command to list out all preflight checks and automatically check if replication and verification are complete before scheduling a planned failover to ensure the process goes smoothly:
gitlab-ctl promotion-preflight-checksEach step is described in more detail below.
Object storage
If you have a large GitLab installation or cannot tolerate downtime, consider migrating to Object Storage before scheduling a planned failover. Doing so reduces both the length of the maintenance window, and the risk of data loss as a result of a poorly executed planned failover.
In GitLab 15.1, you can optionally allow GitLab to manage replication of Object Storage for secondary sites. For more information, see Object Storage replication.
Review the configuration of each secondary site
Database settings are automatically replicated to the secondary site, but the
/etc/gitlab/gitlab.rb file must be set up manually, and differs between
sites. If features such as Mattermost, OAuth or LDAP integration are enabled
on the primary site but not the secondary site, they are lost during failover.
Review the /etc/gitlab/gitlab.rb file for both sites and ensure the secondary site
supports everything the primary site does before scheduling a planned failover.
Run system checks
Run the following on both primary and secondary sites:
gitlab-rake gitlab:check
gitlab-rake gitlab:geo:checkIf any failures are reported on either site, they should be resolved before scheduling a planned failover.
Check that secrets and SSH host keys match between nodes
The SSH host keys and /etc/gitlab/gitlab-secrets.json files should be
identical on all nodes. Check this by running the following on all nodes and
comparing the output:
sudo sha256sum /etc/ssh/ssh_host* /etc/gitlab/gitlab-secrets.jsonIf any files differ, manually replicate GitLab secrets and replicate SSH host keys to the secondary site as necessary.
Check that the correct certificates are installed for HTTPS
This step can be safely skipped if the primary site and all external sites accessed by the primary site use public CA-issued certificates.
If the primary site uses custom or self-signed TLS certificates to secure inbound connections or if the primary site connects to external services that use custom or self-signed certificates, the correct certificates should also be installed on the secondary site. Follow instructions for using custom certificates with secondary sites.
Ensure Geo replication is up-to-date
The maintenance window does not end until Geo replication and verification is completely finished. To keep the window as short as possible, you should ensure these processes are close to 100% as possible during active use.
On the secondary site:
-
On the top bar, select Main menu > Admin.
-
On the left sidebar, select Geo > Sites. Replicated objects (shown in green) should be close to 100%, and there should be no failures (shown in red). If a large proportion of objects aren't yet replicated (shown in gray), consider giving the site more time to complete

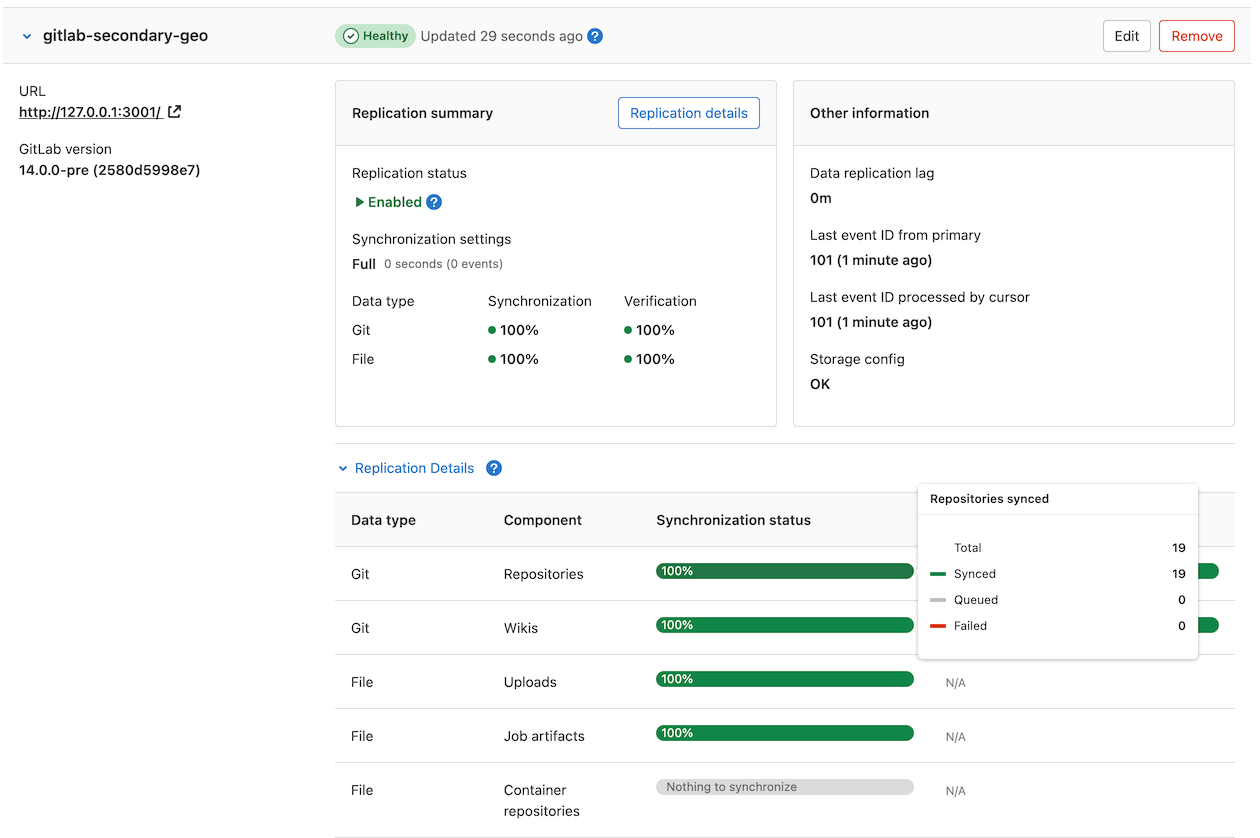
If any objects are failing to replicate, this should be investigated before scheduling the maintenance window. Following a planned failover, anything that failed to replicate is lost.
You can use the Geo status API to review failed objects and the reasons for failure.
A common cause of replication failures is the data being missing on the primary site - you can resolve these failures by restoring the data from backup, or removing references to the missing data.
Verify the integrity of replicated data
This content was moved to another location.
Notify users of scheduled maintenance
On the primary site:
- On the top bar, select Main menu > Admin.
- On the left sidebar, select Messages.
- Add a message notifying users on the maintenance window. You can check under Geo > Sites to estimate how long it takes to finish syncing.
- Select Add broadcast message.
Prevent updates to the primary site
To ensure that all data is replicated to a secondary site, updates (write requests) need to be disabled on the primary site:
- Enable maintenance mode on the primary site.
- On the top bar, select Main menu > Admin.
- On the left sidebar, select Monitoring > Background Jobs.
- On the Sidekiq dashboard, select Cron.
- Select
Disable Allto disable non-Geo periodic background jobs. - Select
Enablefor thegeo_sidekiq_cron_config_workercron job. This job re-enables several other cron jobs that are essential for planned failover to complete successfully.
Finish replicating and verifying all data
NOTE: GitLab 13.9 through GitLab 14.3 are affected by a bug in which the Geo secondary site statuses appears to stop updating and become unhealthy. For more information, see Geo Admin Area shows 'Unhealthy' after enabling Maintenance Mode.
-
If you are manually replicating any data not managed by Geo, trigger the final replication process now.
-
On the primary site:
-
On the top bar, select Main menu > Admin.
-
On the left sidebar, select Monitoring > Background Jobs.
-
On the Sidekiq dashboard, select Queues, and wait for all queues except those with
geoin the name to drop to 0. These queues contain work that has been submitted by your users; failing over before it is completed, causes the work to be lost. -
On the left sidebar, select Geo > Sites and wait for the following conditions to be true of the secondary site you are failing over to:
- All replication meters reach 100% replicated, 0% failures.
- All verification meters reach 100% verified, 0% failures.
- Database replication lag is 0 ms.
- The Geo log cursor is up to date (0 events behind).
-
-
On the secondary site:
- On the top bar, select Main menu > Admin.
- On the left sidebar, select Monitoring > Background Jobs.
- On the Sidekiq dashboard, select Queues, and wait for all the
geoqueues to drop to 0 queued and 0 running jobs. - Run an integrity check to verify the integrity of CI artifacts, LFS objects, and uploads in file storage.
At this point, your secondary site contains an up-to-date copy of everything the primary site has, meaning nothing was lost when you fail over.
Promote the secondary site
After the replication is finished, promote the secondary site to a primary site. This process causes a brief outage on the secondary site, and users may need to sign in again. If you follow the steps correctly, the old primary Geo site should still be disabled and user traffic should go to the newly-promoted site instead.
When the promotion is completed, the maintenance window is over, and your new primary site now begins to diverge from the old one. If problems do arise at this point, failing back to the old primary site is possible, but likely to result in the loss of any data uploaded to the new primary in the meantime.
Don't forget to remove the broadcast message after the failover is complete.
Finally, you can bring the old site back as a secondary.